오늘은 파이썬으로 네이버 쇼핑 상품 크롤링 하는 방법에 대해 알아보겠습니다.

파이썬 네이버 쇼핑 상품 크롤링하기
먼저 크롤링을 하기 위해서는 구글 크롬과 구글크롬드라이버를 다운로드 받아주셔야 합니다.
크롬버전을 확인하기 위해서 인터넷에서 오른쪽 점 세개 버튼을 누르시고 설정으로 들어가줍니다. 그리고 설정에서 크롬 정보를 누르셔서 버전을 확인해줍니다. 그리고 크롬드라이버 홈페이지에서 그와 맞는 버전을 설치해줍니다.
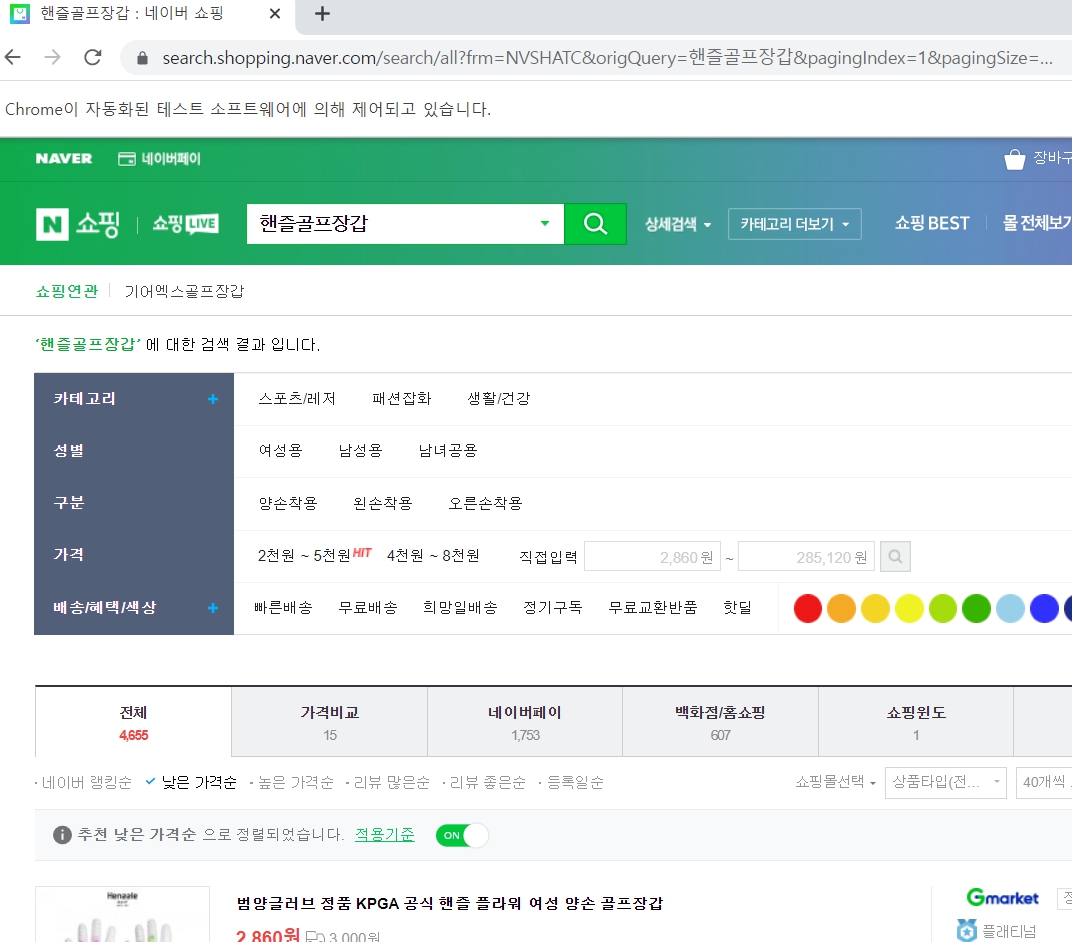
저는 네이버에서 핸즐골프장갑이라고 검색한다음에 낮은가격순으로 확인을 해보는 코드를 작성해보았습니다.
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import pandas as pd
# chromedriver 위치에서 코드작업 필수
chrome_options = Options()
driver = webdriver.Chrome(service=Service(), options=chrome_options)
URL = 'https://search.shopping.naver.com/search/all?frm=NVSHATC&origQuery=%ED%95%B8%EC%A6%90%EA%B3%A8%ED%94%84%EC%9E%A5%EA%B0%91&pagingIndex=1&pagingSize=40&productSet=total&query=%ED%95%B8%EC%A6%90%EA%B3%A8%ED%94%84%EC%9E%A5%EA%B0%91&sort=price_asc×tamp=&viewType=list#'
driver.get(URL)
SCROLL_PAUSE_SEC = 1
# 스크롤 높이 가져옴
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 끝까지 스크롤 다운
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 1초 대기
time.sleep(SCROLL_PAUSE_SEC)
# 스크롤 다운 후 스크롤 높이 다시 가져옴
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
soup = BeautifulSoup(driver.page_source, 'html.parser')
goods_list = soup.select('div.basicList_item__0T9JD')
print(goods_list)
# list들
list_name = []
list_price = []
list_date = []
list_seller = []
list_img = []
list_url = []
for v in goods_list:
item_name = v.select_one('div.basicList_title__VfX3c > a').get('title')
list_name.append(item_name)
item_price = v.select_one('strong.basicList_price__euNoD > span').text
list_price.append(item_price)
item_date = v.select_one('div.basicList_etc_box__5lkgg > span').text.split(' ')[1]
list_date.append(item_date)
if v.select_one('div.basicList_mall_title__FDXX5 > a > img') == None:
item_seller = v.select_one('div.basicList_mall_title__FDXX5 > a').text
else:
item_seller = v.select_one('div.basicList_mall_title__FDXX5 > a > img').get('alt')
list_seller.append(item_seller)
item_URL = v.select_one('div.basicList_title__VfX3c > a').get('href')
list_url.append(item_URL)
driver.close()
df = pd.DataFrame(
{
'상품명': list_name,
'가격': list_price,
'등록일': list_date,
'판매자': list_seller,
'상품 URL': list_url
}
)
df.to_excel(excel_writer='testtest.xlsx')
print(df)
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import pandas as pd
# chromedriver 위치에서 코드작업 필수
chrome_options = Options()
driver = webdriver.Chrome(service=Service(), options=chrome_options)
URL = ' https://search.shopping.naver.com/search/all?frm=NVSHATC&origQuery=%ED%95%B8%EC%A6%90%EA%B3%A8%ED%94%84%EC%9E%A5%EA%B0%91&pagingIndex=1&pagingSize=40&productSet=total&query=%ED%95%B8%EC%A6%90%EA%B3%A8%ED%94%84%EC%9E%A5%EA%B0%91&sort=price_asc×tamp=&viewType=list#'
driver.get(URL)
SCROLL_PAUSE_SEC = 1
# 스크롤 높이 가져옴
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 끝까지 스크롤 다운
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 1초 대기
time.sleep(SCROLL_PAUSE_SEC)
# 스크롤 다운 후 스크롤 높이 다시 가져옴
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
soup = BeautifulSoup(driver.page_source, 'html.parser')
goods_list = soup.select('div.basicList_item__0T9JD')
print(goods_list)
# list들
list_name = []
list_price = []
list_date = []
list_seller = []
list_img = []
list_url = []
for v in goods_list:
item_name = v.select_one('div.basicList_title__VfX3c > a').get('title')
list_name.append(item_name)
item_price = v.select_one('strong.basicList_price__euNoD > span').text
list_price.append(item_price)
item_date = v.select_one('div.basicList_etc_box__5lkgg > span').text.split(' ')[1]
list_date.append(item_date)
if v.select_one('div.basicList_mall_title__FDXX5 > a > img') == None:
item_seller = v.select_one('div.basicList_mall_title__FDXX5 > a').text
else:
item_seller = v.select_one('div.basicList_mall_title__FDXX5 > a > img').get('alt')
list_seller.append(item_seller)
item_URL = v.select_one('div.basicList_title__VfX3c > a').get('href')
list_url.append(item_URL)
driver.close()
df = pd.DataFrame(
{
'상품명': list_name,
'가격': list_price,
'등록일': list_date,
'판매자': list_seller,
'상품 URL': list_url
}
)
df.to_excel(excel_writer='testtest.xlsx')
print(df)

이렇게 코드를 실행해주시면 위 화면처럼 엑셀 화면이 생성되는 것을 확인하실 수 있습니다.
마무리
이상 네이버에서 상품 크롤링 하는 방법에 대해 알아봤습니다.
관련글 더보기
2023.02.19 - [파이썬(Python)] - 파이썬으로 임의의 비밀번호 만드는 프로그램 예시
파이썬으로 임의의 비밀번호 만드는 프로그램 예시
오늘은 파이썬으로 임의의 비밀번호 만드는 프로그램 예시에 대해 알아보겠습니다. 파이썬 임의의 비밀번호 만들기 파이썬에서 임의의 비밀번호 만들기 예시 입니다. 위 코드에서는 먼저 random
lotto4989.tistory.com
'파이썬(Python)' 카테고리의 다른 글
| 파이썬으로 임의의 비밀번호 만드는 프로그램 예시 (0) | 2023.02.19 |
|---|---|
| 파이썬으로 이메일 자동으로 보내는 방법? (0) | 2023.02.14 |
| Python으로 작업 흐름 간소화하기 (반복 작업 자동화) (0) | 2023.02.13 |
| 파이썬 문자열 (0) | 2022.07.13 |
| 파이썬 숫자와 연산자 (0) | 2022.07.12 |